# Compilation
***
To compile the model in a binary file that the DPU can understand, there will be created a compilation script that follows a similar structure as the quantization script but with it's unique parameters. Before that we will only need a DPU description file and the YOLO model quantized and optimized in Tensorflow, which we already have.
{% hint style="info" %}
You can skip the first step involving the creation of the DPU description file since I done it and placed it on the folder "compilation" on the repository". If you are interested you can proceed with the process but you need to bring the Vivado project folder to Ubuntu.
{% endhint %}
So, first, I am going to teach you how to generate the DPU description file. This file has the ".dcf" extension and it contains information's of the DPU based on the Vivado project. On older versions of DNNDK this information would be given by manual input and would be more generic. This file already exists for a limited set of Xilinx boards like the ZCU102 and the ZedBoard but the PYNQ-Z2 is not on that list so the user will have to generate the ".dcf" file by himself.
To generate the DPU description file you will have to use a tool called **Dlet** and there will only be needed a ".hwh" file from the Vivado project. This file can be hard to find but you can generally locate it on a similar path to this {Vivado\_Project\_location}\pynqz2\_dpu\pynqz2\_dpu.srcs\sources\_1\bd\pynqz 2\_dpu\hw\_handoff.
With the possession of the ".hwh" file we can proceed and generate the ".dcf" file with this command:
```
dlet -f {/path/to/Vivado_project}/pynqz2_dpu.hwh {/path/to/output}/pynq-z2.dcf -o
```
This file will obviously be necessary for the compilation process so you have to place it on the "compilation" folder of the repository. Also, you should have noticed a lock symbol on the file that means it is read only. You might change the permissions to read and write to be sure it will work. To do it you right click on the file, go to properties and the permissions.
Permissions of the DPU description file
I also recommend you change the name of the file for something more recognizable.
Next, let's take a look at the compilation script parameters so we can analise it together:
Compilation script scheme
As you can see on the image, the parameter "parser" refers to the framework associated with the model which is Tensorflow in this case. Then in "frozen\_pb" we refer the quantized YOLO model. From the two files generated on the quantization we are interested on the "deploy\_model.pb". The next parameter refers to the ".dcf" file we generated earlier so the system has the idea of which DPU architecture we will be working with. The "cpu\_arch" is relative to the ARM processor architecture of the PYNQ-Z2 which is arm32. The next parameter refers to the desired location of the generated files and I suggest we separate them because they are very important. Then we can allow the program to generate a kernel information file on the "save\_kernel" parameter. "mode" refers to debug or normal mode and I chose normal nut should be interesting to try debug so there are more options enabled on the API. Lastly, the "net\_name" is where we name the resulting binary file.
Now with this information I created a compilation script that matches our needs for this project:
```
# delete previous results
rm -rf ./compile
#conda activate decent
# Compile
echo "#####################################"
echo "COMPILE WITH DNNC"
echo "#####################################"
dnnc \
--parser=tensorflow \
--frozen_pb=./deploy_model.pb \
--dcf=pynqz2_dpu.dcf \
--cpu_arch=arm32 \
--output_dir=compile \
--save_kernel \
--mode normal \
--net_name=yolo
echo "#####################################"
echo "COMPILATION COMPLETED"
echo "#####################################"
```
Then you can execute the compilation process using the `./compile.sh` command. The process shouldn't take more than a few minutes so no worries there.
The resulting files will be stored on the "compile" folder as is in the next image:
Compilation files
The compilation has generated a ".elf" file which is the binary file that represents the compressed Neural Network to the DPU and the remaining files are just informational files. The "yolo\_kernel.info" has indeed some information's about the kernel and the image has the kernel ID and type. These files will be joined with a c++ program to make YOLO work and a Makefile to compile everything and debug the code. We will be addressing in more detail this on the next chapter. For now, you need to:
* Open "Deployment" form the repository;
* Copy the elf file and place it on the "model" folder;
* Copy the "yolo\_kernel.info" and the jpg file to the "info" folder;
{% hint style="info" %}
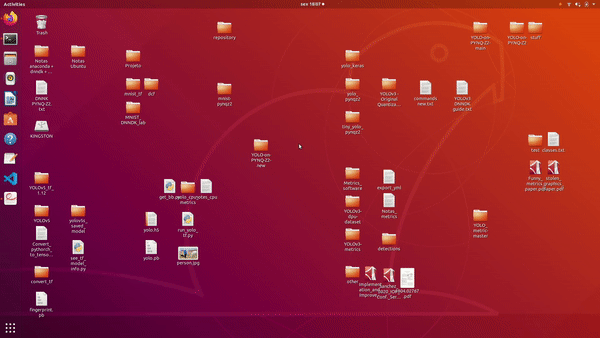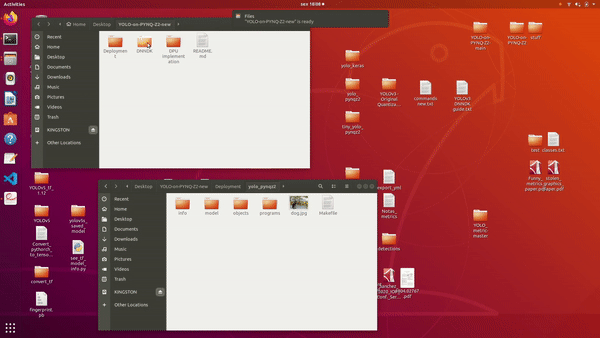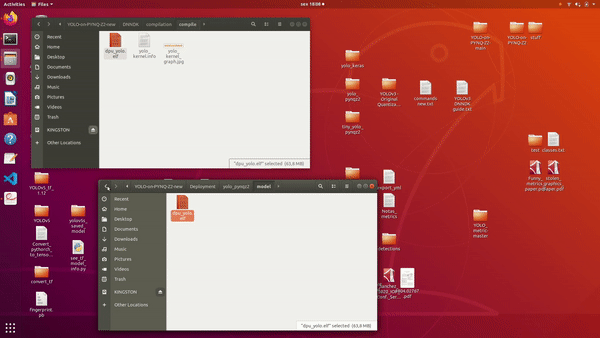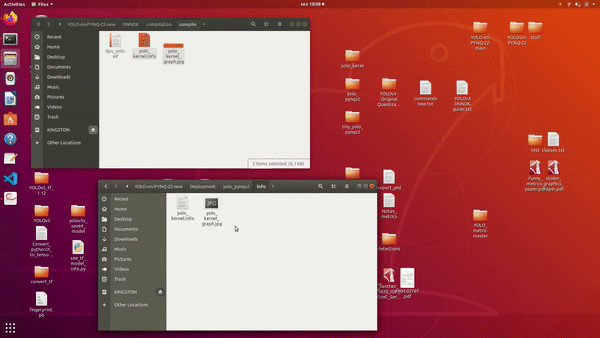
Sorry if you can't see the gif properly. But what i am doing is accessing the Deployment folder and then I right click on the repository and press "Open In New Window". Then I just copy the files to the other window where they are needed.
{% endhint %}
Move required files to the Deployment folder
Deployment folder with necessary files
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://andre-araujo.gitbook.io/yolo-on-pynq-z2/model-optimization-and-compilation/compilation.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.